# Graph-SQL
Граф состоит из узлов (вершин) и ребер (связей). Узлы - конкретные сущности, такие как человек (person) или автомобиль (car). Ребра соединяют узлы друг с другом. В данном примере два типа ребер: друзья (friends) и владелец (owner).
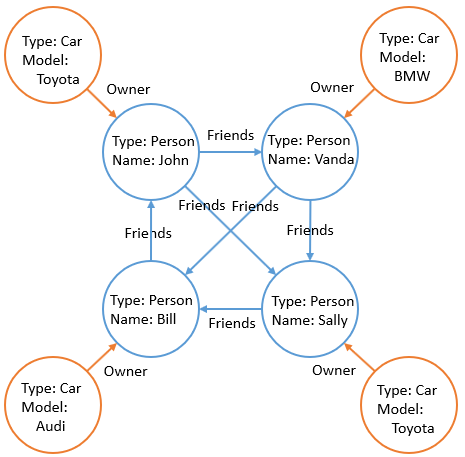
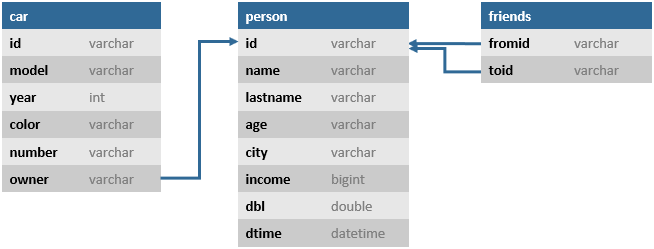
Узлы и ребра (связи) хранятся в таблицах. Связь owner представлена в виде простого поля Foreign Key (связь многие-к-одному). Связь многие-ко-многим friends представлена в виде таблицы специального типа EDGE (См. документ «Демонстрационная база данных»).
Представление графа в виде реляционных таблиц
# Запросы
# MATCH
Graph-SQL - язык для выполнения графовых запросов, являющийся простым расширением SQL. Graph-SQL добавляет новое выражение MATCH.
Начнем с простого пример. Мы хотим найти всех людей имеющих автомобиль и у которых есть друзья имеющие автомобиль той же модели.
SELECT p1.name, p2.name as friendname, c1.model
MATCH (car c1)-[owner]->(person p1)-[friends]->(person p2)<-[owner]-(car c2)
WHERE c1.model = c2.model
Выражение MATCH является паттерном для описания какие объекты и связи нам нужны для выполнения запроса. MATCH заменяет выражение FROM в SQL запросах. Остальные выражения: SELECT, WHERE, ORDER BY, GROUP BY, HAVING, INTO являются обычными выражениями SQL.
В данном примере выражение MATCH описывает что:
- есть некий узел c1 типа car
- c1 по связи owner ссылается на узел p1 типа person
- p1 по связи friends ссылается на узел p2 типа person
- c2 по связи owner ссылается на узел p2
Выражение WHERE добавляет условие c1.model = c2.model
На картинке ниже показан подграф удовлетворяющий данному запросу:
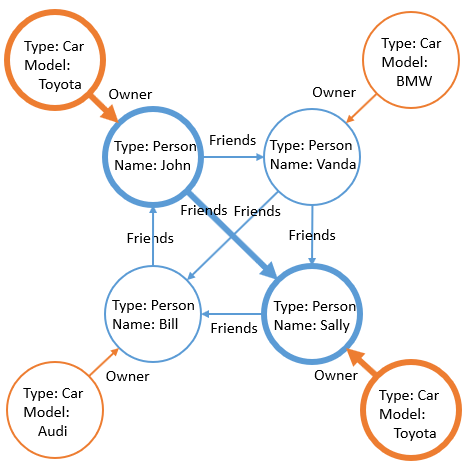
Результат запроса выглядит как и результат обычного SQL запроса SELECT.
| name | friendname | model |
|---|---|---|
| John | Sally | Toyota |
Простое выражение MATCH представляет цепочку узлов и связей. Но что делать если паттерн нельзя представить в виде простой цепочки? Например нам нужно указать несколько связей (больше двух) от узла p1. В этом случае мы можем добавить еще одно выражение MATCH.
SELECT p1.name, p2.name as friendname, c1.model
MATCH (car c1)-[owner]->(person p1)-[friends]->(person p2)<-[owner]-(car c2)
MATCH (p1)-[friends]->(person p3)<-[owner]-(car c3)
WHERE c1.model = c2.model and c3.model = c1.model
Обратите внимание: во втором MATCH не указан тип узла p1 поскольку он уже был описан ранее.
Для удобства, вместо набора MATCH выражений (как в примере выше) можно все паттерны собрать под одним выражением MATCH, указав их через запятую (как в примере ниже).
SELECT p1.name, p2.name as friendname, c1.model
MATCH (car c1)-[owner]->(person p1)-[friends]->(person p2)<-[owner]-(car c2),
(p1)-[friends]->(person p3)<-[owner]-(car c3)
WHERE c1.model = c2.model and c3.model = c1.model
При поиске друзей может понадобиться ограничение на глубину поиска (друзья, друзья друзей, друзья друзей друзей и т.д.).
Стрелка -[friends]-> в выражении MATCH, представляющая ребро графа, может содержать дополнительные параметры глубины:
| выражение | комментарий |
|---|---|
| -[friends]-> | глубина 1 (друзья) |
| -[friends 2]-> | глубина 2 (друзья друзей) |
| -[friends 3]-> | глубина 3 (друзья друзей друзей) |
Дополнительный параметр глубины может указать, что вам нужны и все промежуточные узлы достижимые по связи от одной глубины до другой:
| выражение | комментарий |
|---|---|
| -[friends 2,3]-> | глубина от 2 до 3 (друзья друзей + друзья друзей друзей) |
| -[friends 2,*]-> | глубина от 2 до бесконечности (друзья друзей + друзья друзей друзей + ...) |
| -[friends *]-> | аналогично -[friends 1,*]-> |
Найти всех друзей (а также друзей друзей и друзей друзей друзей) John-а живущих с ним в одном городе.
SELECT p1.name, p2.name as friendname
MATCH (person p1)-[friends 1..3]->(person p2)
WHERE p1.name = 'John' and p1.city = p2.city
# MATCH! (строгий порядок выполнения)
Выражение MATCH! похоже на выражение MATCH, но определяет строгий порядок прохождения по узлам и связям графа.
Рассмотрим запрос: получить всех людей 20 лет, имеющих автомобиль Toyota
SELECT p1.id
MATCH! (person p1, p1.age=20)<-[owner]-(car c1, c1.model='Toyota')
Запрос начинается с поиска всех людей в возрасте 20 лет. Далее для каждого найденого человека по ссылке [owner] берутся все его автомобили и для каждого выполняется сравнение c1.model='Toyota'
При поиске людей может быть использован индекс по полю age. Если условие поиска более сложное могут использоваться несколько индексов одновременно или составные индексы (индексы по нескольким полям) (см. описание SQL)
Выражение MATCH! позволяет оптимизировать выполнение запросов на основании знаний о предметной области. В данном случае мы знаем, что 20 летних людей у нас в базе мало. Также мы имеем возможность отсечь переходы по связям на ранних этапах, существенно упростив запрос. Например, мы хотим получить друзей друзей некоторого человека, таких что и друзья, и друзья друзей живут с ним в одном городе. Плохой алгоритм: возьмем друга, живущего в другом городе, далее возьмем его друзей и лишь в конце будем проверять условия. Хороший алгоритм: запрос будет работать в разы быстрее, если мы сразу же проверим для человека каждого его друга, и если он живет в другом городе то и не будем дальше проверять его друзей.
SELECT p1.id
MATCH! (person p1, p1.id = 'person1')-[friends]->(person p2, p2.city = p1.city)-[friends]->(person p3, p3.city = p1.city)
В добавок к простым SQL условиям выражение MATCH может содержать условие distinct.
SELECT p1.id
MATCH! (person p1, p1.id = 'person1')-[friends]->(person p2, p2.city = p1.city)-[friends]->(person p3, distinct, p3.city = p1.city)
В данном случае distinct означает, что мы хотим получить только уникальные записи p3. Данный вариант distinct отличается от классического SQL и служит для пометки узлов графа, по которым мы уже проходили. Поэтому пользоваться таким вариантом distinct надо с осторожностью. Например, мы хотим получить всех друзей друзей человека, имеющих автомобиль той же марки.
Следующие 2 запроса вернут разный результат:
SELECT distinct p2.id
MATCH! (person p1, p1.id='person1')<-[owner]-(car car1),
(p1)-[friends]->(person px)
-[friends]->(person p2, p1.id != p2.id )
<-[owner]-(car car2, car1.model=car2.model);
SELECT p2.id
MATCH! (person p1, p1.id='person1')<-[owner]-(car car1),
(p1)-[friends]->(person px)
-[friends]->(person p2, distinct, p1.id != p2.id )
<-[owner]-(car car2, car1.model=car2.model);
Первый запрос использует классически SQL distinct. Второй запрос неправильный! Предположим, что person1 имеет два автомобиля: Toyota и VW. Берем первый автомобиль, далее находим некого друга его друга, имеющего автомобиль VW. Условие car1.model=car2.model не срабатывает, но мы уже пометили узел графа, соответствующего данному человеку. Теперь, когда мы вернемся к person1 и возьмем теперь VW, после этого возьмем того же друга друга то обнаружим, что уже были в этом узле и ложно откинем его (хотя он тоже имеет VW).
# Модификация данных графа
# Создание структуры графа
Data Definition Language (DDL) - основные выражения для работы с графом
| Запрос | Комментарий |
|---|---|
| CREATE TABLE DROP TABLE | Создание, удаление таблиц. Таблицы для ребер графа создаются с расширением AS EDGE. |
| ALTER TABLE | Модификация схемы таблицы (добавление, удаление колонок и др.). |
| CREATE INDEX DROP INDEX | Создание, удаление индексов. Вы также можете создать индекс для описания связи многие-к-одному для одного или нескольких полей (для создания связи типа foreign key но без объявления constrain) |
# Добавление или удаление данных
Data Manipulation Language (DML)
| Запрос | Комментарий |
|---|---|
| INSERT INSERT INTO SELECT INTO BULK INSERT | Добавление узлов графа и ребер не отличается от добавления записей в реляционные таблицы. |
| DELETE | Удаление узлов и ребер графа. |
| UPDATE | Модификация значений отдельных колонок записей. |
← SQL Native C/C++ API →